.png&w=3840&q=75)
GraphQL入門① GraphQL Playgroundに触れよう

@ 西川信行
はじめに
今回はGraph QLについてまとめていきます。
頑張っていきましょう。
GraphQL is 何?
最初に、GraphQLとは何かについてざっくりとまとめていきます。
一言で言うと、GraphQLとはFacebookが開発しているWeb APIのための規格で、「クエリ言語」と「スキーマ言語」から構成されます。
クエリ言語 is 何?
まずはウィキペディアからの引用です。
問い合わせ言語(といあわせげんご、英: query language)とは、コンピュータのデータに対して問い合わせをするためのコンピュータ言語である。
データの構造(データモデル)によってさまざまである。たとえば、関係データベースに対する問い合わせ言語は、関係代数の集合演算、比較、ソートといった機能を持つものが多い。
なお、コンピュータのデータベースを扱うためのコンピュータ言語をデータベース言語という。
問い合わせ言語とデータベース言語は、概念的に重なる部分もあるが、同義ではない。
ざっくりと理解するなら、SQLのようにデータベースに対して問い合わせの命令を送る言語のことと考えて問題ないでしょう。しかし、データベースを扱うための言語は「データベース言語」と呼ぶので、それよりも意味が広い言葉のようです。
スキーマ言語 is 何?
今度はコトバンクからの引用です。
《schema language》マークアップ言語で記述する文書の構造定義に用いられる言語。タグや属性などの要素が、どのような役割で用いられているかを定義する。DTDやXMLスキーマが知られる。
ざっくり説明すると、「このファイルはこんな構造になってますよ」ということが書いてあるファイルの書き方のルールのことだと理解しておいて下さい。
Graph QLはこのクエリ言語とスキーマ言語の2つから構成されるWeb APIの規格のことなんですね。
GraphQLはWeb APIの規格のことなので、Web APIの設計モデルであるREST APIと対比されますよね。
何でGraph QLが使われるん?
GraphQLはWeb APIの規格のことです。そこまでは分かりましたよね。
それでは、ここから「なぜGraphQLが使われるのか」を考えてみましょう。
今までのAPI
今まで最も使われていた(現在進行形で最も使われている)Web APIはREST APIです。
REST APIに変わるものとしてGraphQLが生まれてきたのですから、GraphQLはREST APIの何らかの課題を解決するために生まれてきたと考えて差し支えなさそうですよね。
ということで、なぜGraph QLが生まれてきたのかを知るために、REST APIとその問題点について解説していきます。
REST APIとは
REST APIとは、設計原則であるRESTに基づいて設計されたAPIのことです。
RESTは、以下の4つの設計原則があります。
- 全てのリソースは一意なURIで表される(リソースファースト)
- ステートレスであること
- 情報の内部に別の情報や別の状態へのリンクを含めることができること
- 情報の操作(CRUD)にHTTPメソッド(GET, POST, PUT, DELETE)を利用すること
軽く説明います。
全てのリソースが一意なURIで表される、という意味がなんとなく分かるでしょうか。
これは、何らかのリソース、つまりはデータに対してアクセスする際に、そのリソースごとの一意なURIを持つということです。
RESTな設計思想では、リソースというデータの実体を重要視して考えます。リソースに対して、そのリソースの場所を一意なURIで表現し、そのURIに対してHTTPメソッドを送ることでリソースを操作します。
例えば、 nishikawa というデータに対して何らかの処理を行う際に、どのようにアクセスすれば良いでしょうか。まず考えられるのは、このデータを取得するURI、このデータを更新するURL、このデータを新規作成するURI、このデータを削除するURIを作成することです。以下のようになります。
users/getNishikawa // 取得
users/updateNishikawa // 更新
users/createNishikawa // 新規作成
users/deleteNishikawa // 削除
このように nishikawa という一つのリソースに対して、4つのURIを設定します。そして、この各々のURIにアクセスすることで、このリソースの取得・更新・新規作成・削除を行う、というものです。
このように定義してもよいのですが、RESTなAPIはこのような定義を行いません。
RESTなAPIは、リソースに対して一意なURIを定義するんでしたね。
users/nishikawa // 一意なURLを定義
そして、このURIに対してアクセスする際に、主に4つのHTTPメソッドを使用します。
例えば、users/nishikawa に対してHTTPメソッドのGETリクエストを送りデータの取得を行う、ということが考えられますし、users/nishikawa に対してHTTPメソッドのPOSTリクエスを行いデータの更新を行う、ということも考えられます。
このように、リソースというデータの実体に対して一意のURLを割り振り、このデータの実体に対してGET・POST・PUT・DELETE等の統一インターフェースによりリソースの操作を行うようなAPIの規格のことをREST APIと呼びます。
ここまででなんとなくREST APIが理解できたでしょうか。
それでは次に、REST APIの抱える課題について解説します。
REST APIが抱える課題
過剰な取得
REST APIは、データを取得する際に必要がないデータまで取得してします可能性があります。
というのも、REST APIで取得するデータは一般的にデータベースの都合がやデータの構造が優先され、「フロントエンドの画面を描画するのに必要なデータを提供する」という設計思想のもと作成されたものでは無いからです。
例えば、スター・ウォーズの登場人物の名前と身長の一覧を表示させる画面を描画したいとします。
その際、スカイウォーズの登場キャラクターであるルーク・スカイウォーカーのデータを提供するAPIであるhttps://swapi.co/api/people/1 に対してGETリクエストを送ります。
データの実体は面倒くさいので省略しますが、このAPIを叩くと「名前」と「身長」だけではなく、ルーク・スカイウォーカーにまつわる全てのデータが返却されます。例えば、出演したスターウォーズのバージョンやスターシップの種類などのデータです。
今回作成するフロントエンドのページを描画するのに必要なデータは「名前」と「身長」だけですが、REST APIからしてみれば、そのようなフロントエンド側の都合は知ったことではありません。
このように、ページを描画するためにAPIを叩いてデータを取得するのはいいものの、API側の都合で無駄なデータを返却するというのは往々としてよくあります。
GraphQLでは必要なフィールドを指定してデータを取得するため、このような過剰な取得は起きづらいです。
過小な取得
また、過剰な取得と同様に、REST APIでは取得してきたデータが少な過ぎる、ということがよくあります。
例えば、スター・ウォーズのルーク・スカイウォーカーが出演する映画のタイトル一覧を描画する画面を作成する場合を考えましょう。
当然、スター・ウォーズのルーク・スカイウォーカーが出演する映画のタイトル一覧を、APIを叩いて取得する必要があります。https://swapi.co/api/people/1/ のデータを取得すると、ルーク・スカイウォーカーが出演している映画のURIのリストを取得することができます。
しかし、今回取得したいデータは映画のタイトル一覧です。そのため、取得したURIのリストに再びGETリクエストを送って、映画の情報を取得する必要があります。
そして、映画の情報を取得するAPIを叩くと、映画のタイトルだけではなく映画の情報全てが送られてきます。ここまでで、ルーク・スカイウォーカーのデータを取得するAPIを一回叩き、そのAPIから送られてきたルーク・スカイウォーカーが出演している映画のURIをn回叩きました。
必要だったのは映画のタイトルだけだったにも関わらず、n + 1回のデータの取得が行われました。また、映画のタイトルだけではなく、映画の登場人物を取得する必要がある場合は、更に映画のデータを取得するAPIから取得された「登場人物のURIのリスト」から、m回のGETリクエストを送る必要があります。
ここまでで、1 + n + (n x m) 回のクエリを発行することになりました。その結果、レスポンスが遅くなってユーザー体験が低下してしまいますよね。
GraphQLでは必要なデーアを入れ子構造のクエリで取得するため、このようなことは起きづらいです。
RESTのエンドポイントの管理が面倒くさい件
先程の例で、既存のAPIからルーク・スカイウォーカーが出演している映画のタイトルを取得する方法を解説しました。
このようにデータを取得してきてもよいのですが、「映画のタイトル一覧」というフロントエンドのページを描画するために、新たに「あるキャラクターに基づく映画のタイトル一覧」を取得できるAPIを発行しても構いません。
例えば、以下のようなURIが考えられます。
/api/character-with-movie-title // あるキャラクターに紐づく映画のタイトル一覧を取得するAPI
このようなAPIをフロントエンドエンジニアと都度相談して発行するケースも考えられます。しかし、正直なところ面倒臭いですよね。
エンドポイントが増幅していきますし、名前の管理もややこしくなります。GraphQLは単一のエンドポイントに対してクエリを送るため、エンドポイントの管理は簡単です。
ここまでで、なんとなくGraphQLが使われる理由が理解できたと思います。
次は、GraphQLをお手軽に試せるデベロッパーツールであるGraphQL Playgroundについて解説してきます
その次に、GraphQLの利点について解説していきます。
GraphQL Playgroundを使ってみよう
それでは次にGraphQL Playgroundを使ってみましょう。
以下のURLより、GraphQL Playgroundをダウンロードするサイトにアクセスして下さい。
https://www.electronjs.org/apps/graphql-playground
左のダウンロードボタンでローカルにダウンロードできます。GraphQL Playgroundはブラウザでも動くツールなので、必ずしもローカルにダウンロードする必要はないですが、気分的にダウンロードしたいのでダウンロードします。
GraphQL Playgroundを起動した後は、URL ENDPOINTを選択し、https://graphql-pokemon2.vercel.app を入力してOPENを行いましょう。これで、ポケモンのデータを取得するGraphQLのAPIを指定することができました。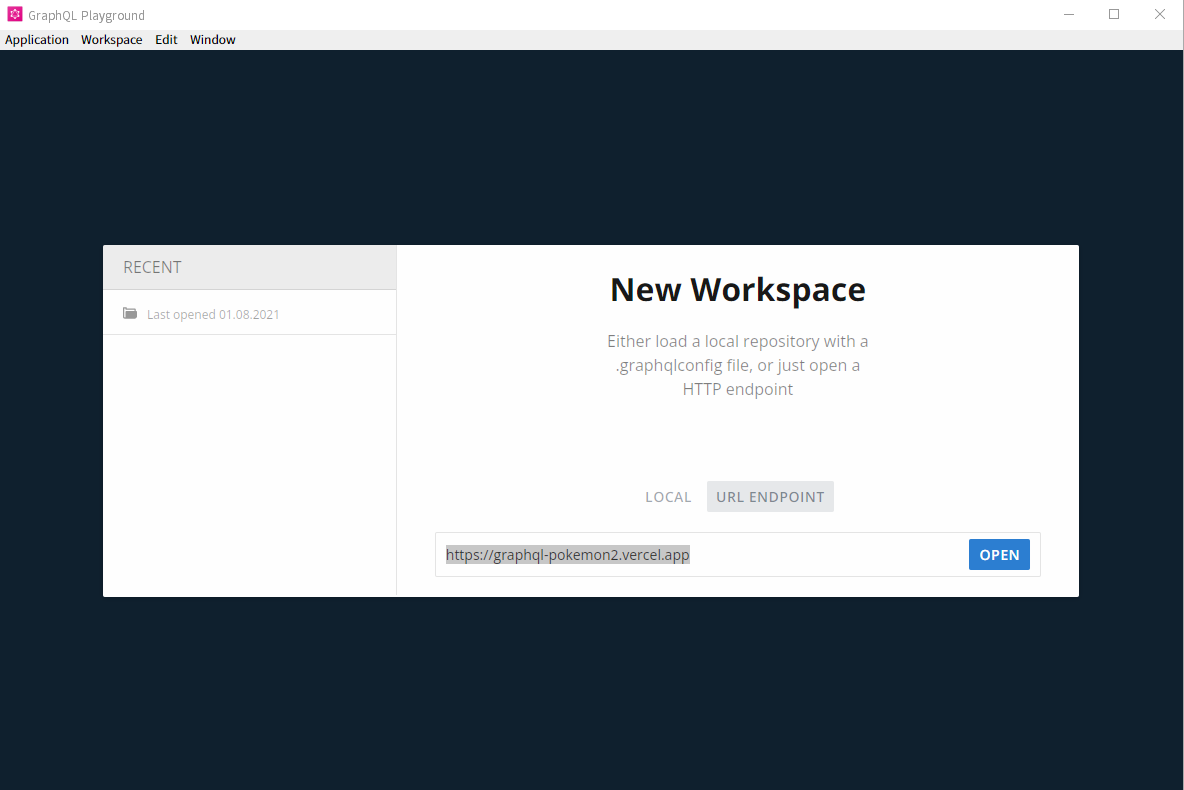
以下のような画面になります。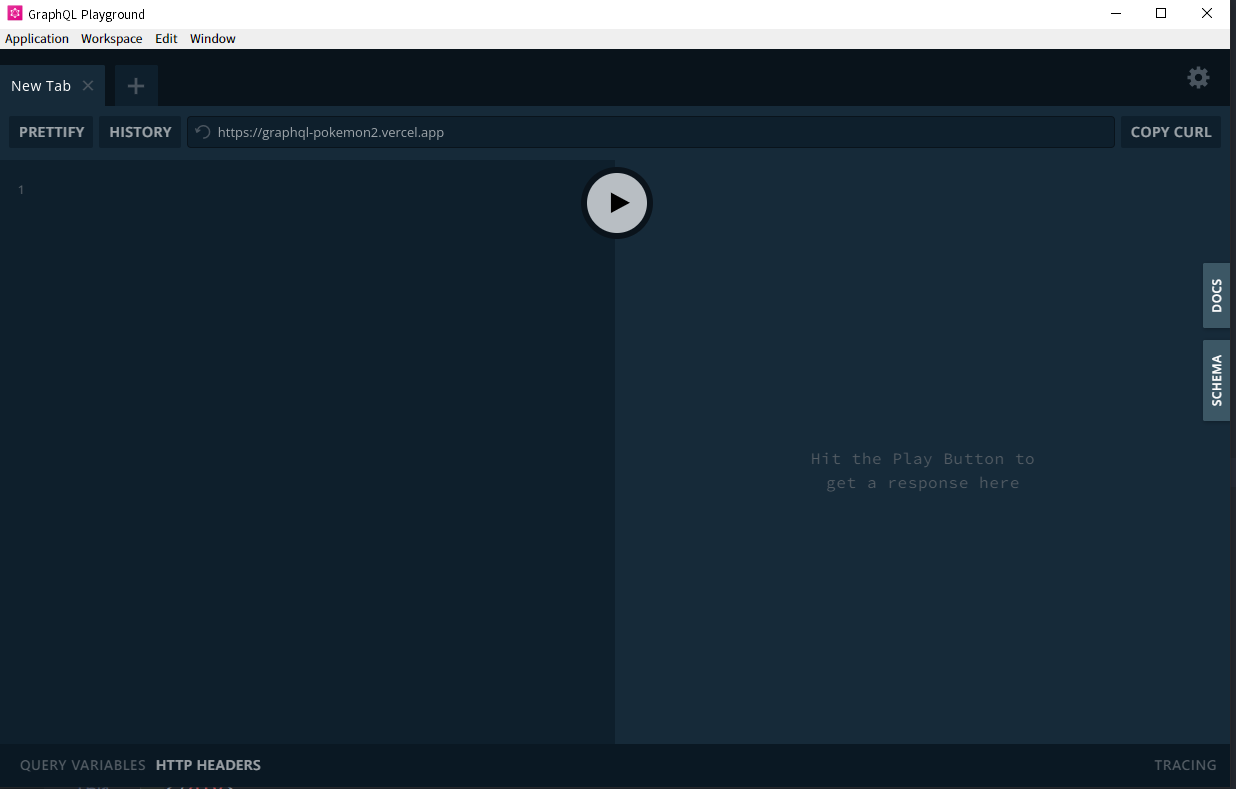
それでは、一つづつ領域を確認してみましょう。
クエリを記述する場所
左の領域はクエリを記述する場所です。
クエリとは、GraphQLがAPIに送る命令のことで、データの取得を行うQueryや、データの新規作成・更新・削除を行うMutation、API側の変更を検知してフロントに通知するSubscriptionなどがあります。
それらのクエリを記述する場所は、左の領域です。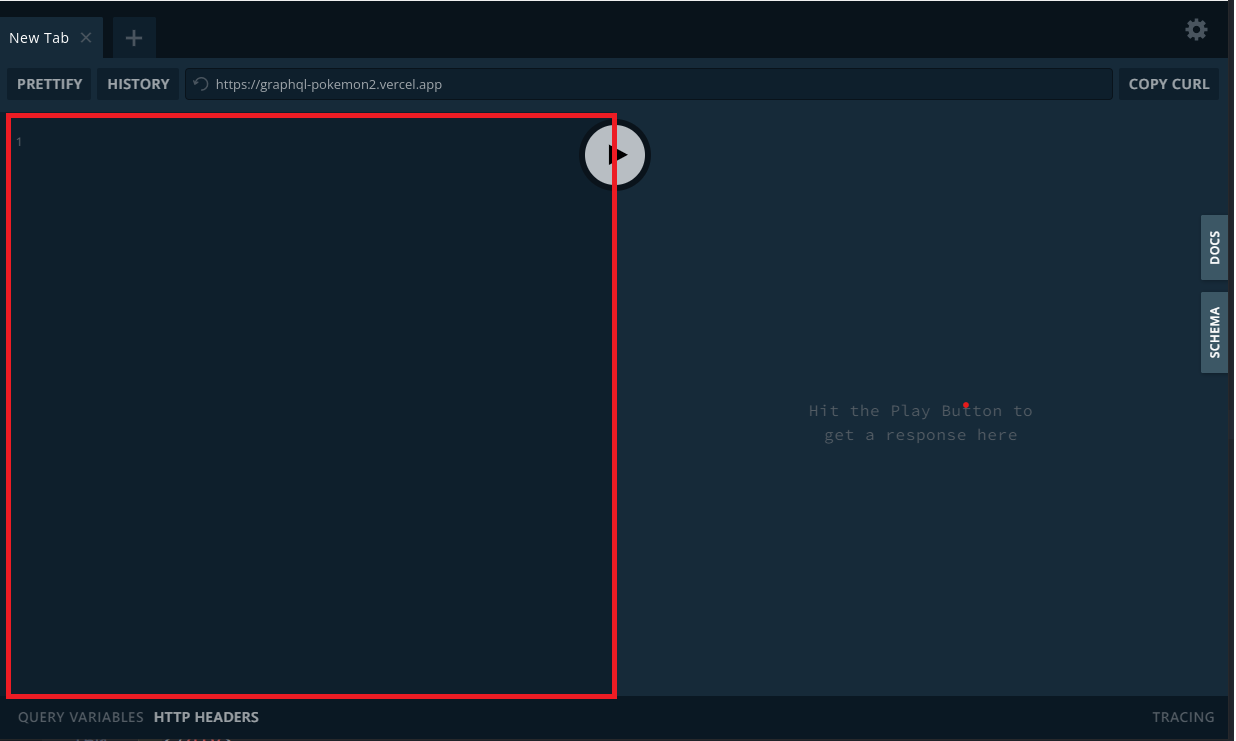
クエリ変数を定義する場所
GraphQLには、クエリ変数というものがあります。
クエリ変数は、Query・Mutation・Subscriptinoなどのトップレベルのクエリの引数として渡すことができる変数であり、オブジェクト形式で定義します。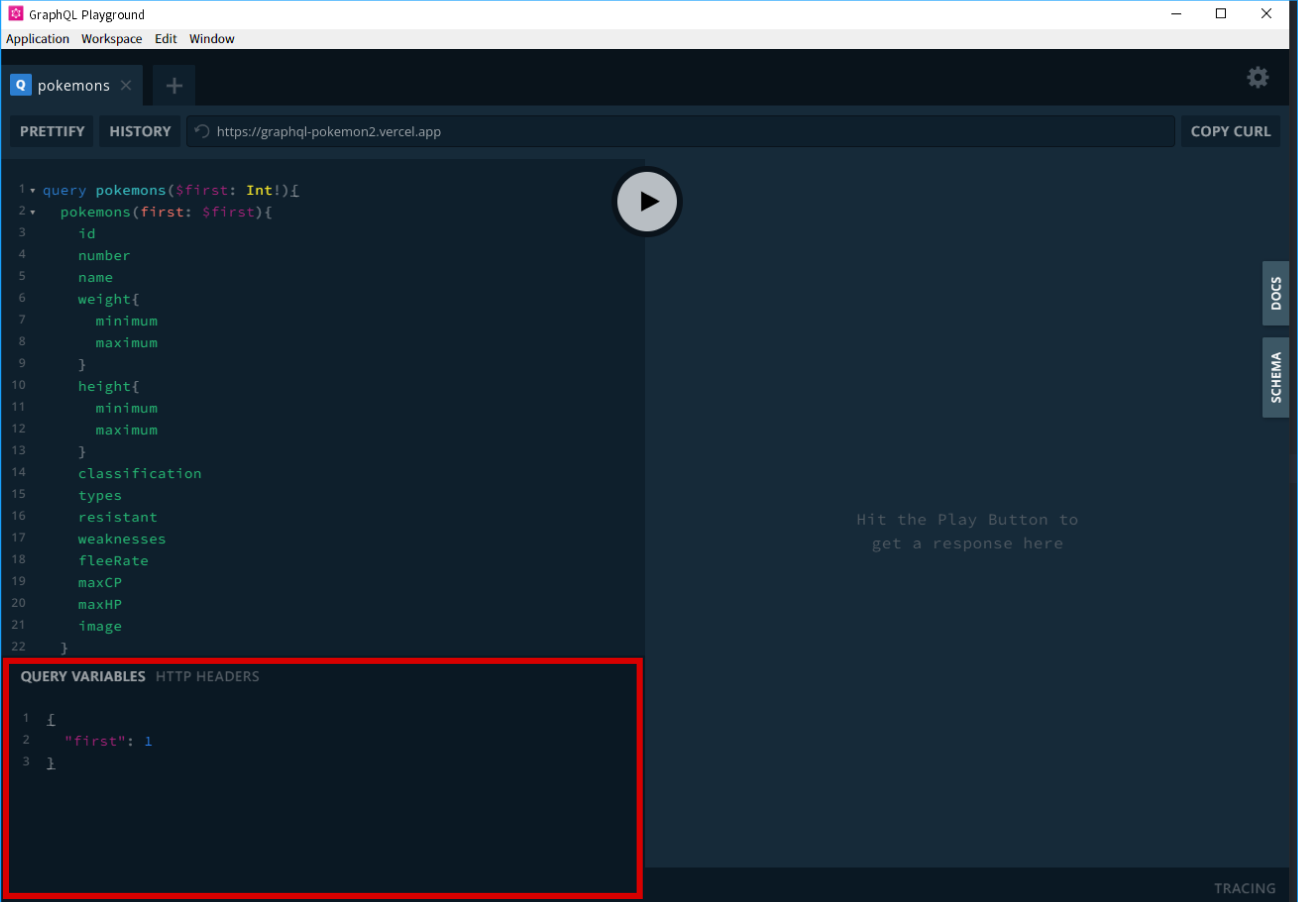
APIから取得したデータが表示される場所
GraphQLのAPIを叩いて取得してきたデータは、右側の領域に表示されます。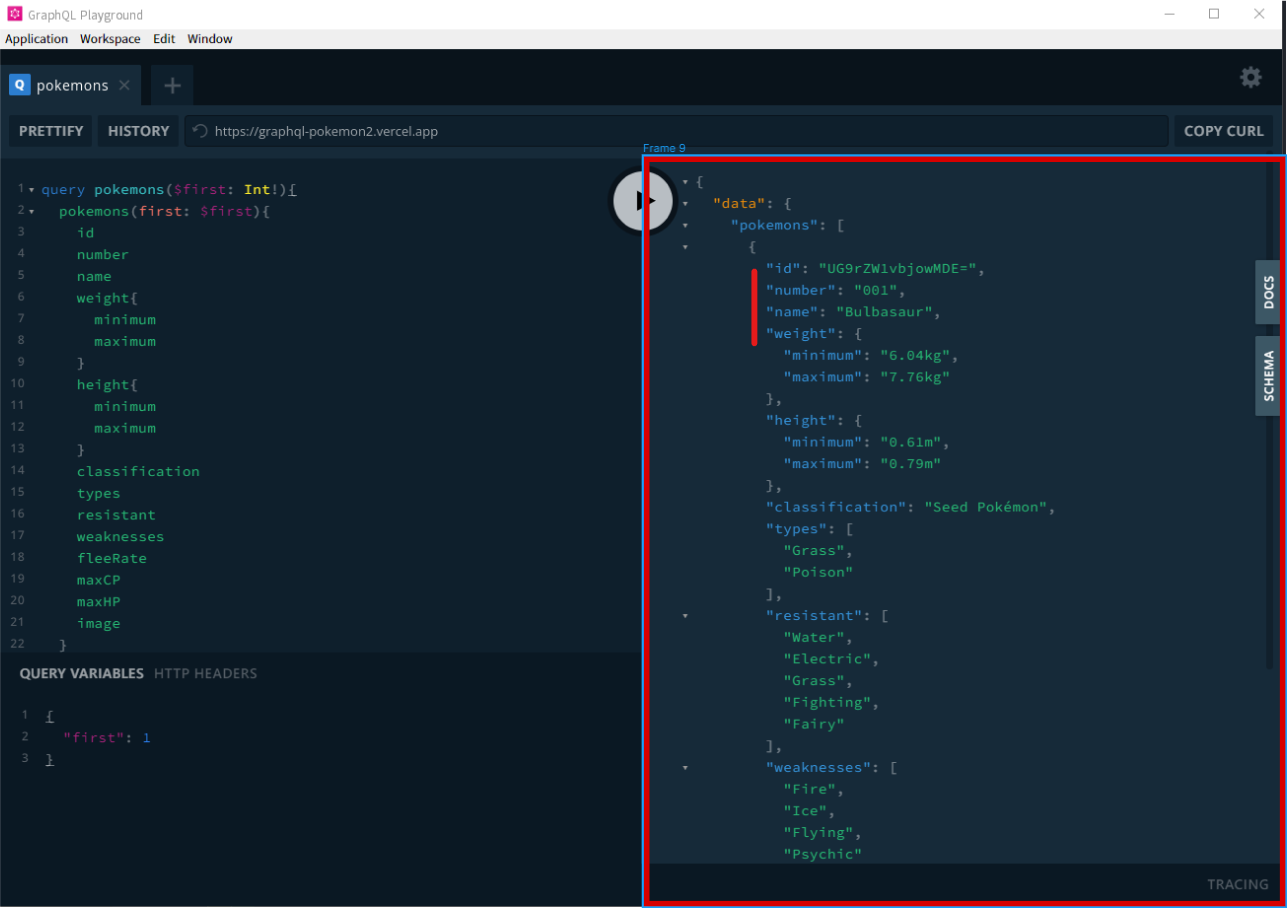
DOCS、SCHEMA
GraphQLの右側の領域であるDOCSとSCHEMAを用いることで、APIのスキーマの構造を確認し、送信するべきクエリを判断することができます。
まずはDOCSを確認してみましょう。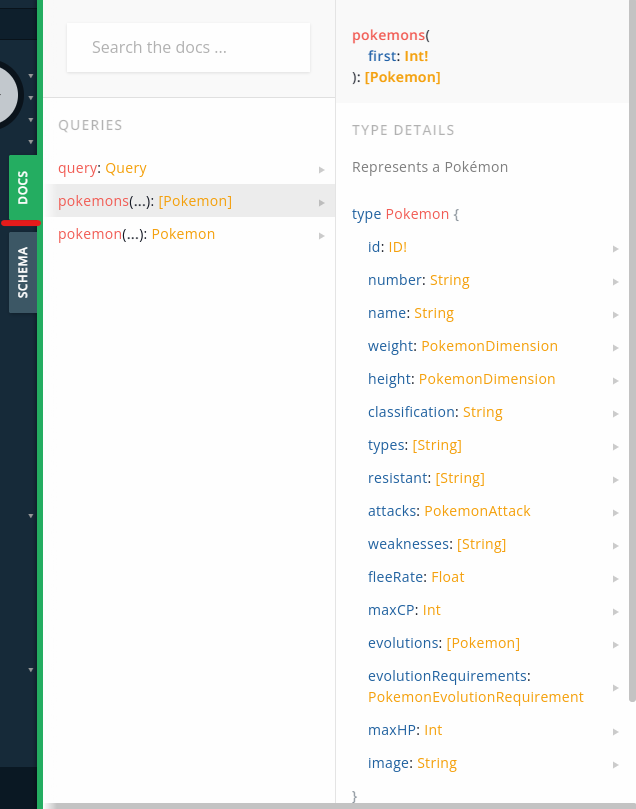
queryの中に、pokemontsというフィールドとpokemonというフィールドが存在するのが確認できますね。また、pokemontsというフィールドはfirstという整数型を引数にもち、戻り値としてPokemon型のリストを返却することが確認できます。また、Pokemon型の中身を確認することもできていますね。
これを元に、クエリを定義してみましょう。
query {
pokemons(first: 2){
name
types
}
}
まず最初にquery を指定しています。クエリのトップで指定するのは、データの取得を行うqueryか、データの新規作成・更新・削除を行うmutationか、データのサブスクリプションを行うsubscriptionです。今回はデータの取得を行うqueryを指定しています。今回、queryで指定できるフィールドはpokemonsとpokemonの2つです。今回はpokemonsを指定しています。
フィールド値としてpokemonsを指定した場合、返却されるデータの方はPokemonというデータ型のリストになっています。
今回は、Pokemon型のデータの内、nameとtypesというフィールド値のみを取得します。そのため、返却されるデータは、Pokemon型のデータの内、nameとtypeというフィールド値のみを取得したオブジェクトのリストになります。
また、pokemonsというフィールド値に引数として整数型の2を渡してあげることで、取得するデータのフィルタリングを行っています。
このクエリをエンドポイントに対して送ると、以下のデータが返却されます。
{
"data": {
"pokemons": [
{
"name": "Bulbasaur",
"types": [
"Grass",
"Poison"
]
},
{
"name": "Ivysaur",
"types": [
"Grass",
"Poison"
]
}
]
}
}
このように、クエリで指定したデータが取得されていることが分かります。また、DOCSを確認することで、どのようにクエリを書けばよいのかも分かりやすいです。
ついでに、SCHEMAも確認しましょう。
これは、GraphQLの作成者が記述したものです。GraphQLは、クエリ言語とスキーマ言語から構成されるWeb APIの規格のことでしたね。先程、データを取得するために記述したのがクエリ言語です。以下のSCHEMAは、GraphQLの作成者が記述したスキーマ言語です。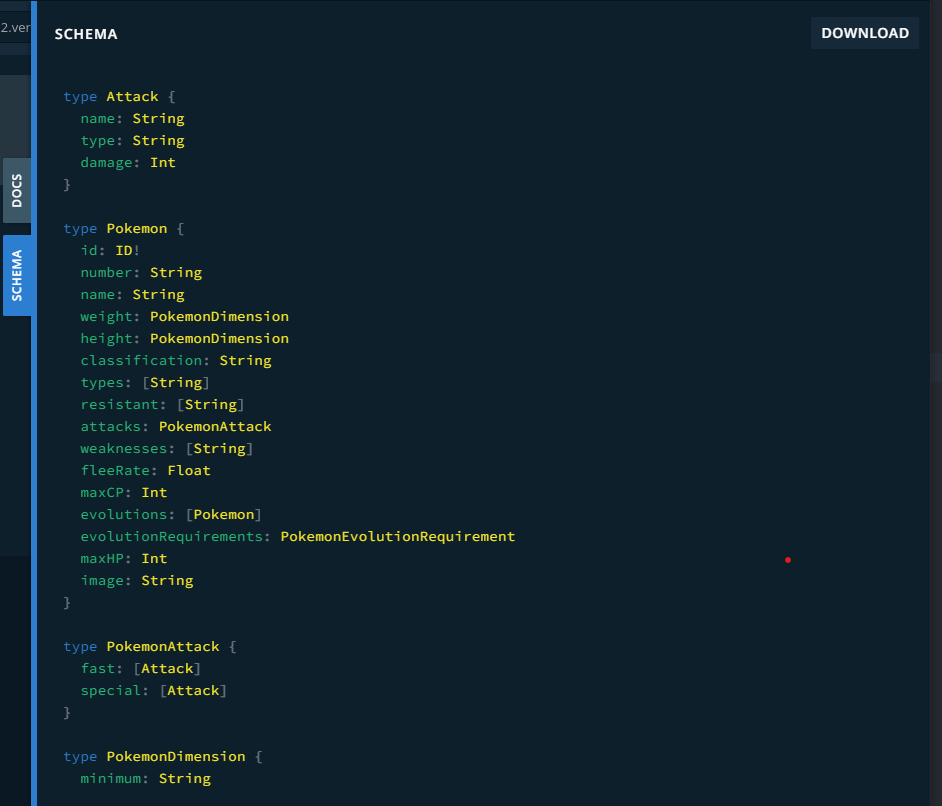
このように、SCHEMAにはGraphQLで取り扱う全てのデータが型として記述されています。データは木の構造になっており、トップのデータ方はQuery・Mutation・Subscriptionのいずれかが担っています。
GraphQLのスキーマは、クエリに対応しています。ここでは解説しませんが、GraphQLのスキーマはリゾルバと呼ばれる関数とも対応しており、リゾルバもスキーマに対応するように記述します。
クエリはスキーマに対応するように記述され、そのクエリが実行されると対応するリゾルバが実行されることにより、データが返却されます。リゾルバとスキーマはGraphQLの設計者が記述するもので、フロントはそれに対してクエリを発行するだけです。
クエリをスキーマに対応するように記述し、またクエリの実行により発火するリゾルバもスキーマに対応するように記述します。それにより、スキーマを通じてGraphQL設計者が、GraphQL仕様者に対して、APIの使い方を伝えることができます。
GraphQL仕様者が記述するクエリと、そのクエリにより発火するリゾルバをスキーマに紐付けることで、スキーマがバックエンドとフロントエンドを繋ぐドキュメントとしての役割を果たします。
それでは次に、GraphQLの利点について解説していきます。
GraphQLの利点
クエリとレスポンスに対応関係がある
GraphQLの利点の一つとして、クエリとレスポンスに対応関係があることが挙げられます。
先程GraphQL Playgroundを使用する際に確認したように、クエリとそのレスポンスには明確な対応関係があります。クエリをわざわざオブジェクト形式で書くというのは冗長なように見えますが、返却されるデータがオブジェクト形式のデータであることを考えると、妥当なようにも感じます。
クエリを書く際には、スキーマに対応するように記述します。スキーマは、Query・Mutation・Subscriptionをトップにおいた入れ子の構造になっているため、クエリもそのスキーマに対応するように記述します。
クエリとレスポンスに明確な対応関係があることで、後からコードを読む際にAPIのリファレンスに目を通さなくても返却されるデータがなんとなく理解できます。
これは物凄く大きなメリットです。
スキーマの存在・スキーマの利用をサポートするツールの充実度
GraphQLの最大の特徴は、スキーマが存在することです。また、そのスキーマの中には各々の型の説明も記述する事ができます。
GraphQL Foundationが提供するGraphiQL(グラフィクル)というIDE(総合開発環境)や先ほど使用したGraphQL Playground等のツールを使えば、クエリを発行してその結果を確認するのみならず、スキーマを通じたドキュメントの作成やクエリの補完機能等を利用することができます。
これらの機能も、スキーマを持つというGraphQLの特性によるものです。
ここまでで、なんとなくGraphQLについて理解できたと思います。
さて、ここからGraphQLの本格的な解説を行っていこうと思ったのですが、流石に長くなってきたのでここで一旦終了します。
次は、GraphQLのクエリの書き方について解説していきたいと思います。

.png&w=1920&q=75)
.png&w=1920&q=75)
.png&w=1920&q=75)